But do LLMs think?
2024 November 8
See all posts
After the release of gpt-o1, which showed stunning 1807 rating
on CodeForces, a renowned programming website. This rating would place gpt-o1 above 93% of the website's competitive users. At that moment, I thought: do LLMs really think or simply remember? With a large enough model, you can solve every problem on the internet, yet it will underperform on the unseen problems.
So I head out to find out. I wanted to test gpt on a dataset, then rephrase the problems and test once again to see if the results will change.
I downloaded a HumanEval dataset and spent some time figuring out how to make a workflow.
Firstly, for each problem, I generated a code via OpenAI's API and gpt-4. I used this prompt:
''' "role": "system",
"content": (
"You are an assistant skilled in Python programming. "
"Provide the full code"
"Don't write any examples or test the function."
)'''
I didn't use gpt-4o as I thought it would be too easy for a 2-year-old benchmark, and I didn't use gpt-1o because I don't have an API for it. For each problem via entry_point and gpt's code I generated a .py file, as every problem's statement was in Python.
Then, I needed to test it. Fortunately, the HumanEval dataset was very easy to use, and testing was implemented fairly easy. My first results were:
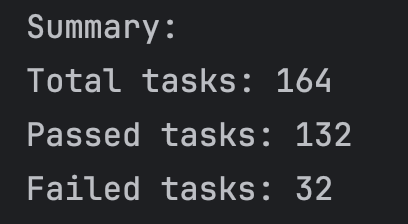
132 correct, 32 incorrect - which is 80.5% percent accuracy, or 19.5% misses, you choose.
Then, I needed to rephrase the problems. Firstly, I wanted to translate the problems twice, from English to French then from French to English again. This way the meaning will be preserved, yet the exact problem statement will be changed.
But It could break problems' structure and used gpt-4. I told it to rephrase the problems, preserving the meaning, and after a few minutes, I had rephrased the dataset.
Then I ran the exact same test, and I got unexpected results:
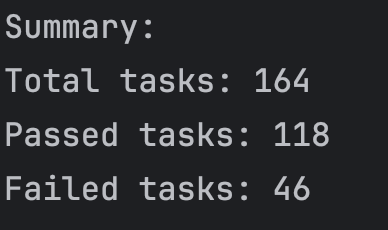
Accuracy rate has dropped from 80.5% to 72.0%, a 10.6% decrease. Mainly, this was caused by gpt-4, for some reason, providing the differently syntax solutions, which wouldn't work.
Of course, that may not be because of rephrasing, but because of the randomness of gpt-4 generations.
This was just a first test, and in the future, I will take more advanced dataset - parse CodeForces problems ranging from 800 to 1600 rating, use 5-shot testing, where LLM may fix the issues, and use various models and not just gpt-4.
But do LLMs think?
2024 November 8 See all posts
After the release of gpt-o1, which showed stunning 1807 rating on CodeForces, a renowned programming website. This rating would place gpt-o1 above 93% of the website's competitive users. At that moment, I thought: do LLMs really think or simply remember? With a large enough model, you can solve every problem on the internet, yet it will underperform on the unseen problems.
So I head out to find out. I wanted to test gpt on a dataset, then rephrase the problems and test once again to see if the results will change.
I downloaded a HumanEval dataset and spent some time figuring out how to make a workflow.
Firstly, for each problem, I generated a code via OpenAI's API and gpt-4. I used this prompt:
I didn't use gpt-4o as I thought it would be too easy for a 2-year-old benchmark, and I didn't use gpt-1o because I don't have an API for it. For each problem via entry_point and gpt's code I generated a .py file, as every problem's statement was in Python.
Then, I needed to test it. Fortunately, the HumanEval dataset was very easy to use, and testing was implemented fairly easy. My first results were:
132 correct, 32 incorrect - which is 80.5% percent accuracy, or 19.5% misses, you choose.
Then, I needed to rephrase the problems. Firstly, I wanted to translate the problems twice, from English to French then from French to English again. This way the meaning will be preserved, yet the exact problem statement will be changed.
But It could break problems' structure and used gpt-4. I told it to rephrase the problems, preserving the meaning, and after a few minutes, I had rephrased the dataset.
Then I ran the exact same test, and I got unexpected results:
Accuracy rate has dropped from 80.5% to 72.0%, a 10.6% decrease. Mainly, this was caused by gpt-4, for some reason, providing the differently syntax solutions, which wouldn't work.
Of course, that may not be because of rephrasing, but because of the randomness of gpt-4 generations.
This was just a first test, and in the future, I will take more advanced dataset - parse CodeForces problems ranging from 800 to 1600 rating, use 5-shot testing, where LLM may fix the issues, and use various models and not just gpt-4.